
Multi Head Attention이란?
Self - Attention이 여러개 있는 것을 말한다. 그러면 Self - Attention이 뭐고, Attention이 무엇인지 알아보자.
Attention이란?
문장에 2개가 있을 때 A 문장의 특정 단어가 B 문장에서 특정 단어와 관련된 정도를 말한다.
아래와 같이 특정 단어끼리의 관련된 정도를 수치화 한것이다.

그렇다면, Self - Attention이란?
한 시퀀스 내에서 각 토큰끼리 계산되는 문맥정보

Self - Attenion은 어떻게 구하나?
Attention을 구하기 위해서는 Q(qeury), K(key), V(value)를 우선적으로 구하고 해당 값을 수식을 통해 Attention을 계산해야한다.
각 의미하는 것은 아래 사진의 설명과 같다.
다시 말해서, Q는 내가 다른 토큰과 어떤 관계인지 궁금해서 질문하는 토큰이고, K는 그 질문을 받는 토큰이고, V는 그 토큰에 대한 정보를 의미한다.

그럼 Q, K, V를 어떻게 구하고 이를 바탕으로 그 결과를 구하는지 알아보자.
1) Q, K, V 구하기
Q, K, V는 Wq, Wk, Wv(가중치)와 토큰을 곱해서 나오게 된다. 해당 가중치는 초기에는 무작위 값이며, 추후 학습되어 올바른 Q, K, V를 구할 수 있게 된다.

2) Q, K, V를 통해서 특정한 공식을 활용해서 Attention 구하기
1번으로 구해진 값을 통해서 아래의 공식을 활용해서 Q와 K의 관계정도를 계산하고, 그 값에 V를 곱해서 실제 정보에서 어느정도의 관련이 있는지를 도출하게 된다.

3) 위 수식과정을 시각화를 통해서 살펴보자.

Q와 K를 행렬곱해서 어텐션 스코어를 구한다.
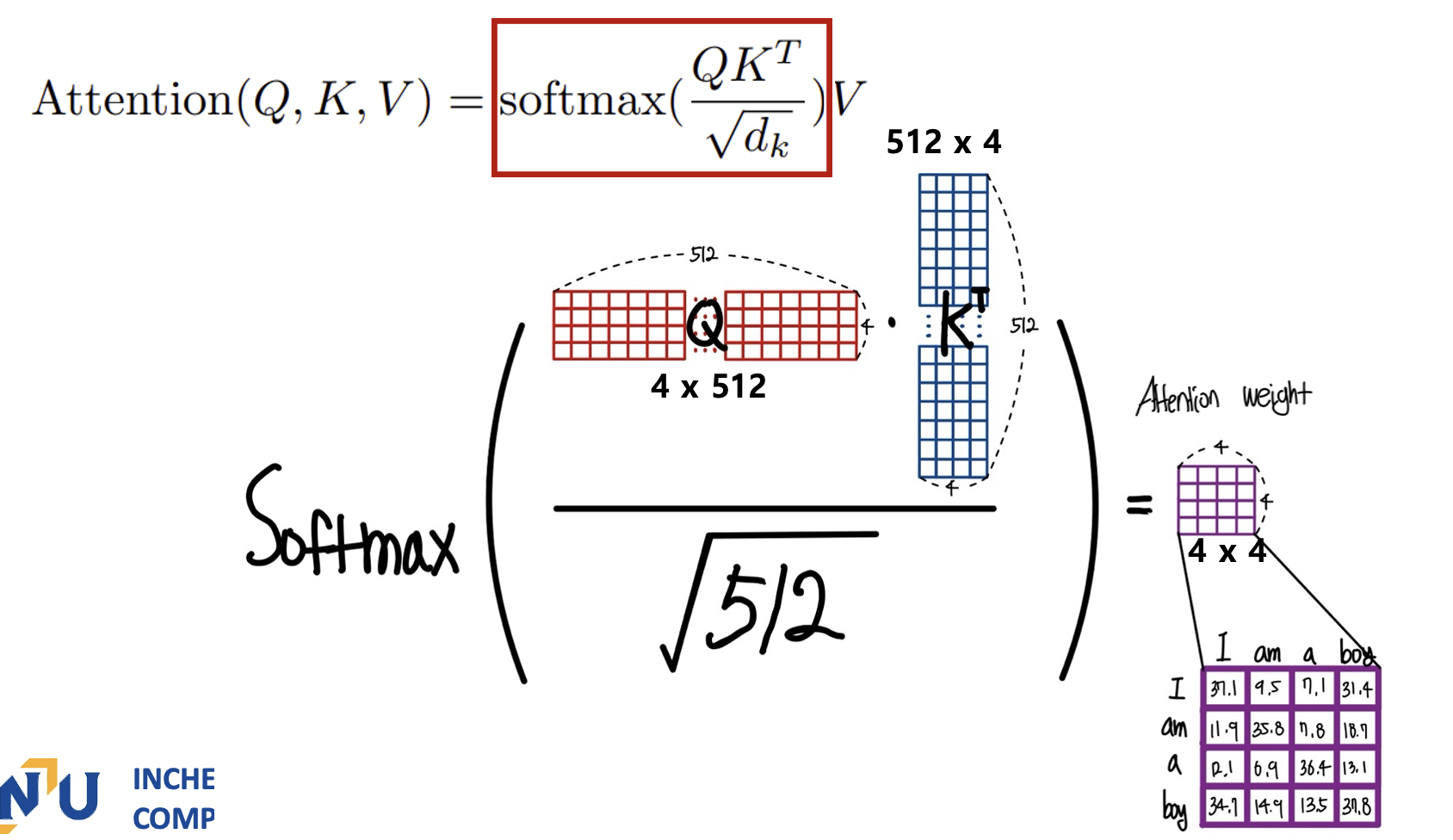
해당 값을 스케일링한 값을 Softmax에 넣어서 어텐션 가중치를 구한다.

이렇게 구해진 어텐션 가중치를 V와 행렬곱해서 어텐션 벡터를 생성해준다.
이렇게 구해진 어텐션 벡터는 토큰 각각에 대해서 계산한 문맥 정보를 원본 임베딩 벡터에 업데이트한 벡터라고 할 수 있다.
여기까지, self - attention으로 연관도를 계산해봤는데, 그러면 multi는 무슨 말일까?
multi란, 당연하게도 여러 개를 의미한다. 기존의 self - attention은 하나의 시점에서 연관도를 계산했지만, Multi가 붙으면 여러 시점에서 연관도를 계산하는 것이다 .
예를 들어, 원래는 주어 - 동사 관계만 확인 했다면 더 추가해서 동사 - 목적어 관계등 더 다양한 시점에서 연관도를 살펴보는 것이다.
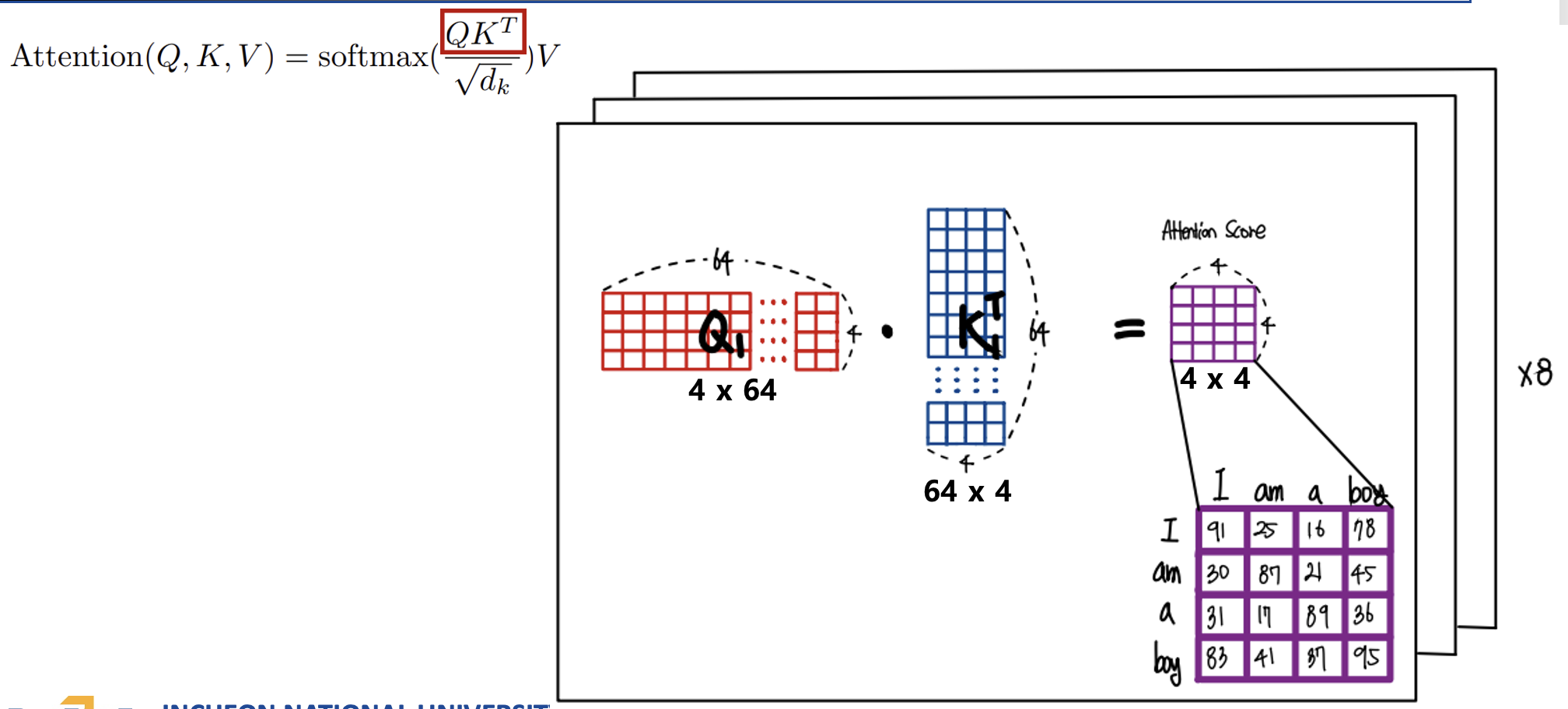
해당 논문에서 헤드가 총 8개로 쓰이기 때문에 각 헤드별로 셀프 어텐션을 해서 어텐션 벡터를 구한다음 구해진 모든 벡터를 옆으로 이어주고 최종적인 가중치를 공해서 벡터를 구해주게된다.
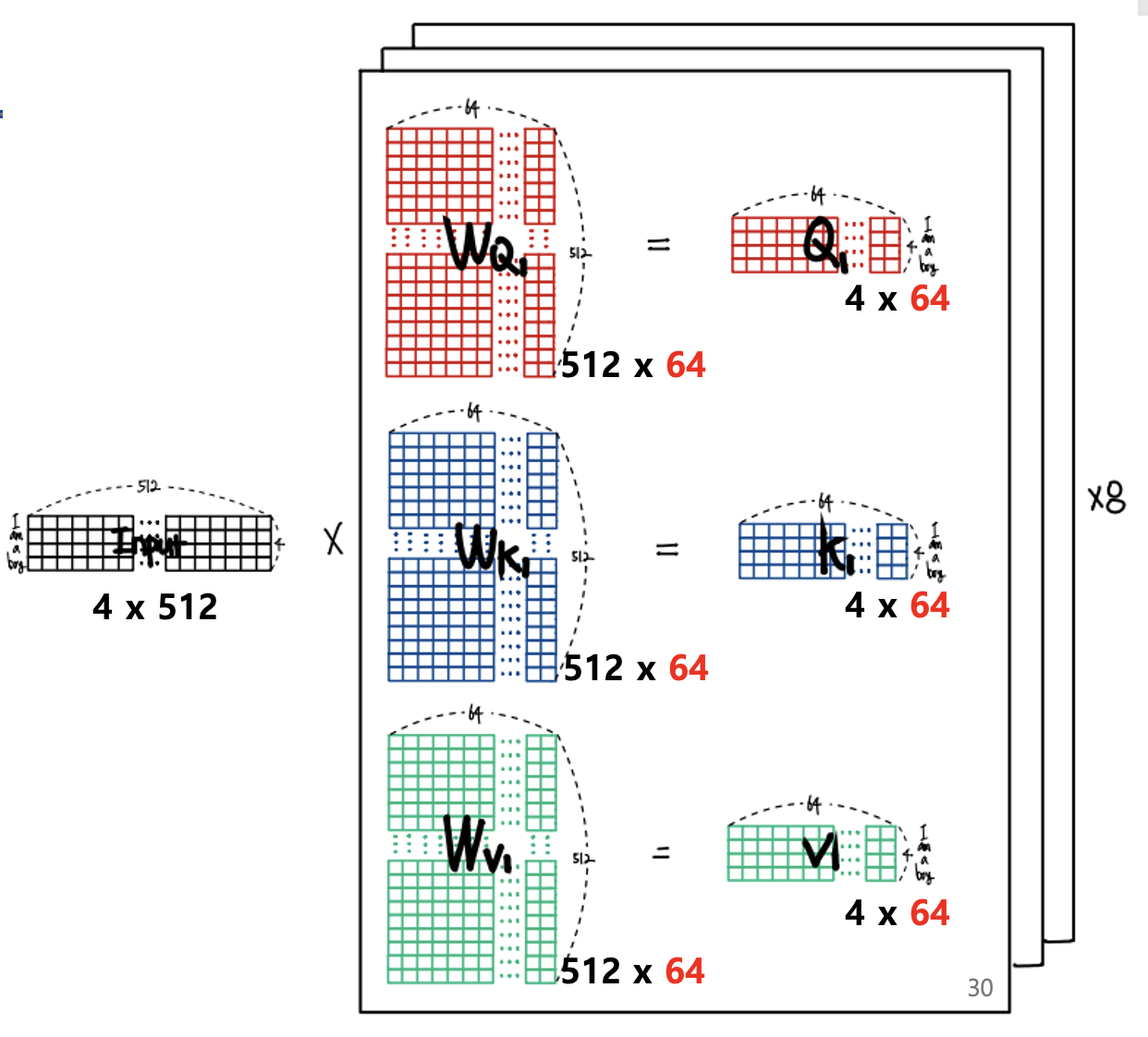
여기서 멀티헤드 어텐션을 할 때는 싱글 헤드와는 다르게 임베딩 벡터의 차원을 헤드로 나눈 차원을 각 헤드의 Q K V로 사용한다.



'논문 > Transfomer' 카테고리의 다른 글
| Transfomer - Cross Multi-Head Attention (0) | 2025.02.25 |
|---|---|
| Transfomer - Feed Forward (0) | 2025.02.25 |
| Transfomer - Masked Multi Head Attention (0) | 2025.02.25 |
| Transfomer - Input Embedding & Positional Encoding (0) | 2025.02.25 |
| Transfomer의 전체적인 아이디어 해석 (0) | 2025.02.25 |



